
Naive Bayes Classifier Algorithm And Assumption Explained
In contrast to other machine learning algorithms that run through multiple iterations in order to converge towards some solution, naive bayes classifies data solely based off of conditional probabilities. Naive bayes has the following advantages:
- extremely fast for both training and making predictions
- interpretable
- doesn’t require hyperparameter tuning
When deciding whether to use naive bayes, you should consider whether the naive assumption actually holds (very rare in practice) and whether the data you’re working with has a high number of dimensions.
Bayes Theorem
Often times, we want to know the probability of some event, given that another event has occurred. This can be expressed symbolically as P(E|F). If two events are not independent then the probability of both occurring is expressed by the following formula.

For example, suppose you are drawing two cards from a standard deck of 52 cards. Half of all cards in the deck are red and half are black. These events are not independent because the probability of the second draw depends on the result of the first.
P(E) = P(black card on first draw) = 25/52 = 0.5
P(F|E) = P(black card on second draw | black card on first draw) = 25/51 = 0.49
Using this information, we can calculate the probability of drawing two black cards in a row as:

Baye’s theorem is one of the most common applications of conditional probabilities. For instance, baye’s theorem is used to calculate the probability that a person who tests positive on a screening test for a particular disease actually has the disease. Bayes theorem can be expressed as:

You would use this formula if you already know P(A), P(B) and P(B|A) but want to know P(A|B). For example, say we’re testing for a rare disease that infects 1% of the population. Medical professionals have developed a highly sensitive and specific test, which is not quite perfect.
- 99% of sick patients test positive
- 99% of healthy patients test negative
Bayes theorem tells us that:

Suppose we had 10,000 people, 100 are sick and 9,900 are healthy. Moreover, after giving all of them the test we’d get 99 sick people testing sick, but 99 healthy people testing sick as well. Thus, we’d end up with the following probabilities.
p(sick) = 0.01
p(not sick) = 1 - 0.01 = 0.99
p(+|sick) = 0.99
p(+|not sick) = 0.01
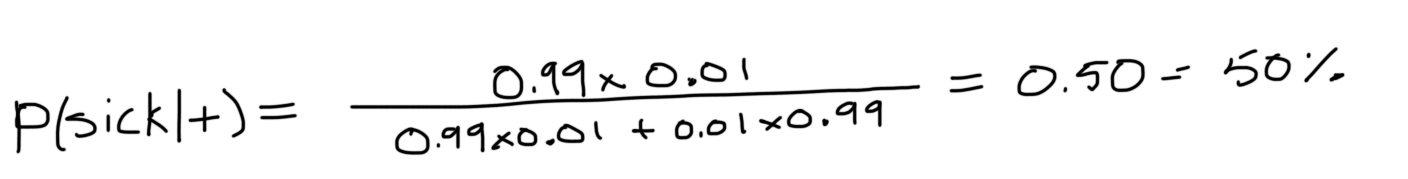
Spam Filter For Individual Words
Naive bayes is commonly used to construct spam filters that classify emails as spam or ham (not spam). For instance, we might develop a spam filter that will categorize an email as spam or not depending on the occurrence of some word. For example, if an email contains the word Viagra, we classify it as spam. If on the other hand, an email contains the word money, then there’s an 80% chance that it’s spam.
According to Bayes Theorem, the probability that an email is spam given that it contains “word”.

Although, we don’t know the value of the denominator offhand, it can be calculated using the following formula. In plain English, it says that the probability of finding the word is the probability of finding the word in a spam email multiplied by the probability that an email is spam, plus the probability of finding the word in a ham email multiplied by the probability that an email is ham.

Thus, the formula becomes:

The training set contains a sufficient amount of information to calculate the right hand side of the equation.
p(spam)
Number of emails that are classified as spam
p(ham)
Number of emails that are classified as ham (not spam)
p(word|spam)
Number of spam emails that contain “word”
p(word|ham)
Number of ham (not spam) emails that contain “word”
Spam Filter That Combines Words
In practice, it’s often not enough to base our classification off of the occurrence of a single word. Some words are harmless by themselves. It’s more when they’re used in conjunction with specific other words that we should classify them as spam. For example, to filter out emails based off the fact that they contain the word “girl”, would end up putting the emails related to your daughter’s soccer team in your spam folder. Ideally, we’d be able to target specific sentences such as “attractive girls in your area”.
Naive Assumption
More often than not, we won’t have the exact sentence with the appropriate label in our training set. In other words, if we’re trying to determine whether an email containing “attractive girls in your area” should be classified as spam or not, we’d look through our training data to see if there were any emails with that sentence that were already classified as spam. If there aren’t any, we have two options, either get more data or calculate the probability given by looking at every word in the sentence.
In order to make the math simpler, we make the naive assumption that words in the text are independent of one another. In other words, the fact that certain words are contained in the text has no impact on the probability of finding a given word in the text. In reality however, certain words will have a tendency to be used together. For example, if you find the word model in an article on machine learning, it’s likely that you will find the words accuracy and train as well.

The probability that an email contains spam given that it contains both the words “attractive” and “girls” can be written as follows:

Code
We’ll start off by importing the required libraries.
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metricsIn the proceeding example, we’ll being using a corpus of news articles. Fortunately, sklearn provides a simple API for importing the data.
newsgroups = fetch_20newsgroups()As the name implies, the news articles are broken up into 20 categories.
print(newsgroups.target_names)
The corpus contains over 11,000 documents.
print(newsgroups.filenames.shape)
To get an idea of what we’re working with, let’s print the first document.
print(newsgroups.data[0])
To make things simpler, we’ll work with a subset of the categories.
categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space']train_newsgroups = fetch_20newsgroups(subset='train', categories=categories)
train_X = train_newsgroups.data
train_y = train_newsgroups.targettest_newsgroups = fetch_20newsgroups(subset='test', categories=categories)
test_X = test_newsgroups.data
test_y = test_newsgroups.targetNext, we use the TfidfVectorizer class to parse the words contained in each document and rank them in terms of relevance. If you’d like to find out more about how TF-IDF works, I go over it in detail in the proceeding post.
Natural Language Processing: Feature Engineering Using TF-IDF
_Natural Language Processing (NLP) is a sub-field of artificial intelligence that deals understanding and processing…_medium.com
vectorizer = TfidfVectorizer()
train_vectors = vectorizer.fit_transform(train_X)
test_vectors = vectorizer.transform(test_X)We use Multionmial naive bayes since we’re trying to classify data into multiple categories. In contrast to other machine learning algorithms, the training process for naive bayes is virtually instantaneous.
classifier = MultinomialNB()
classifier.fit(train_vectors, train_y)We use the f1 score to measure our model’s performance.
predictions = classifier.predict(test_vectors)score = metrics.f1_score(test_y, predictions, average='macro')
Additionally, we can write a function that will predict what class a sentence belongs to.
def predict_category(sentence):
sentence_vector = vectorizer.transform([sentence])
prediction = classifier.predict(sentence_vector)
return train_newsgroups.target_names[prediction[0]]As you can see, the model correctly classifies the sentence under computer graphics.
predict_category('determining the screen resolution')
Final Thoughts
Naive bayes is particularly well suited for classifying data with a high number of features. Unlike other machine learning models, naive bayes requires little to no training. When trying to make a prediction that involves multiple features, we simply the math by making the naive assumption that the features are independent.